← Back to Portfolio
Jobot
Here is the GitHub link to my project! : @Hugo69md/jobot
CONTEXT
As a 5th year engineering student actively searching for an end-of-studies internship in Data and Supply Chain, I was spending a significant amount of time every day on repetitive job-hunting tasks: browsing job platforms, reading offer descriptions, evaluating whether each one matched my profile, tailoring my CV and cover letter for every application, and then actually applying. This manual process was extremely time-consuming and inconsistent — some days I would miss good opportunities simply because I couldn't keep up with the volume of new postings.
I needed a solution that could:
- Automatically scrape internship offers from job platforms on a daily basis, without any manual intervention.
- Intelligently score and rank each offer against my profile using AI, so I could focus only on the most relevant opportunities.
- Generate tailored CVs and cover letters as ready-to-send PDFs, with experience descriptions and skills sections dynamically adapted to each specific offer.
- Notify me in real time via a mobile interface, allowing me to review each offer and approve or reject applications on the go.
- Run entirely autonomously in the cloud on a schedule, requiring zero daily effort from me.
THE PROJECT
Jobot is a fully automated, end-to-end job application pipeline built in Python. The entire system is orchestrated through a single main.py entry point that runs 5 sequential steps, each one modular and independent.
Step 1 — Scraping (Scrapy + Playwright): A custom Scrapy spider with Playwright (headless Chromium) scrapes internship listings from job platforms. It navigates JavaScript-rendered pages, extracts offer titles, company names, descriptions, URLs, and exports everything into a structured internships.json file.
Step 2 — AI Analysis (Ollama Qwen 3.5 / GLM 4.7 flash): The core intelligence of the project. Each scraped offer goes through a multi-step AI pipeline: domain classification (Data vs. Supply Chain), structured extraction of missions and required skills, scoring on 5 weighted criteria (out of 100), intelligent selection of my most relevant experiences, AI-tailored rewriting of each experience description to match ATS keywords the offer, skills section optimization and custom cover letter generation. The AI is strictly prompted to never fabricate skills or experiences absent from my structured cv.json file using sspecific master prompts, temperatures, max outout token & enforcing it to ask for its reasoning.
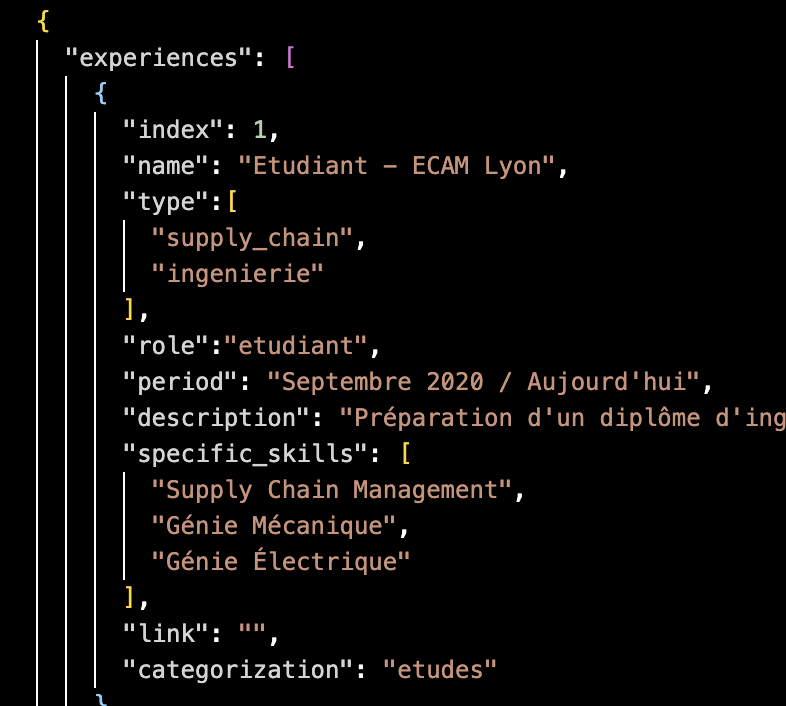
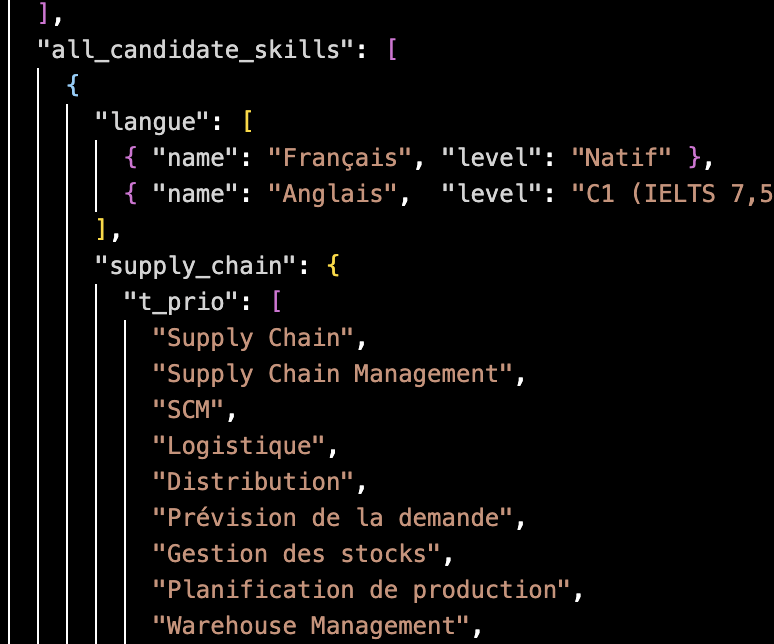
The cv.json file is the single source of truth for the AI. It contains all my experiences (indexed, typed by domain, with specific skills and categorization), a prioritized skills taxonomy organized into top priority, priority, and bonus tiers for both Data and Supply Chain domains, as well as my personal information. The AI reads this structured data to build every tailored application.
Step 3 — PDF Generation (ReportLab): For each offer scoring above the threshold (80/100), the system automatically generates two professional PDF documents: a tailored CV with photo, dynamically selected experiences, rewritten descriptions, and an offer-specific skills section, as well as a personalized cover letter. Each offer gets its own subfolder with all generated files.
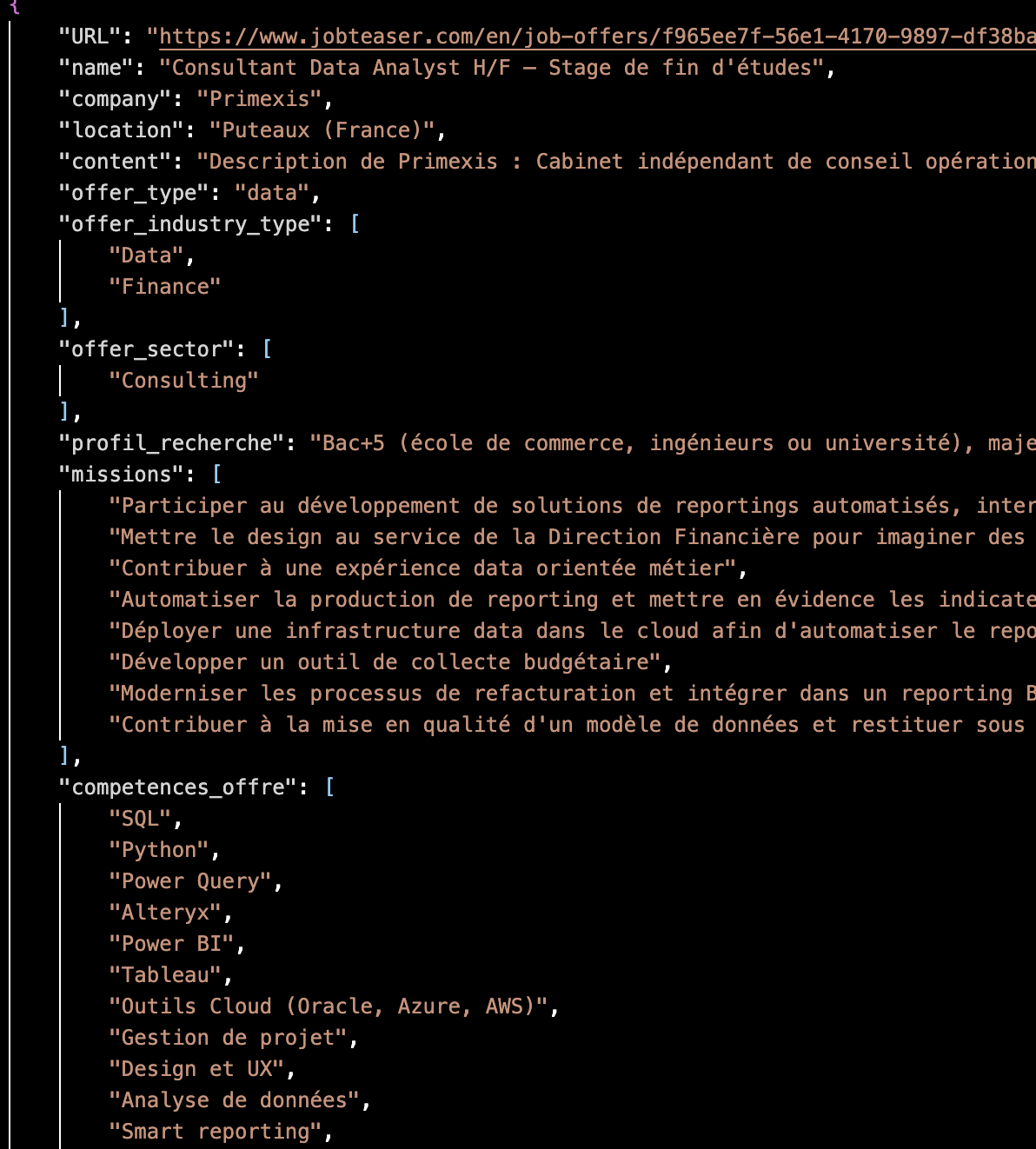
Here is an example of the enriched output for a single offer. The AI has classified the offer, extracted its missions and required skills, scored it against my profile, selected the best-matching experiences, and rewritten their descriptions — all stored in a structured JSON ready for PDF generation.
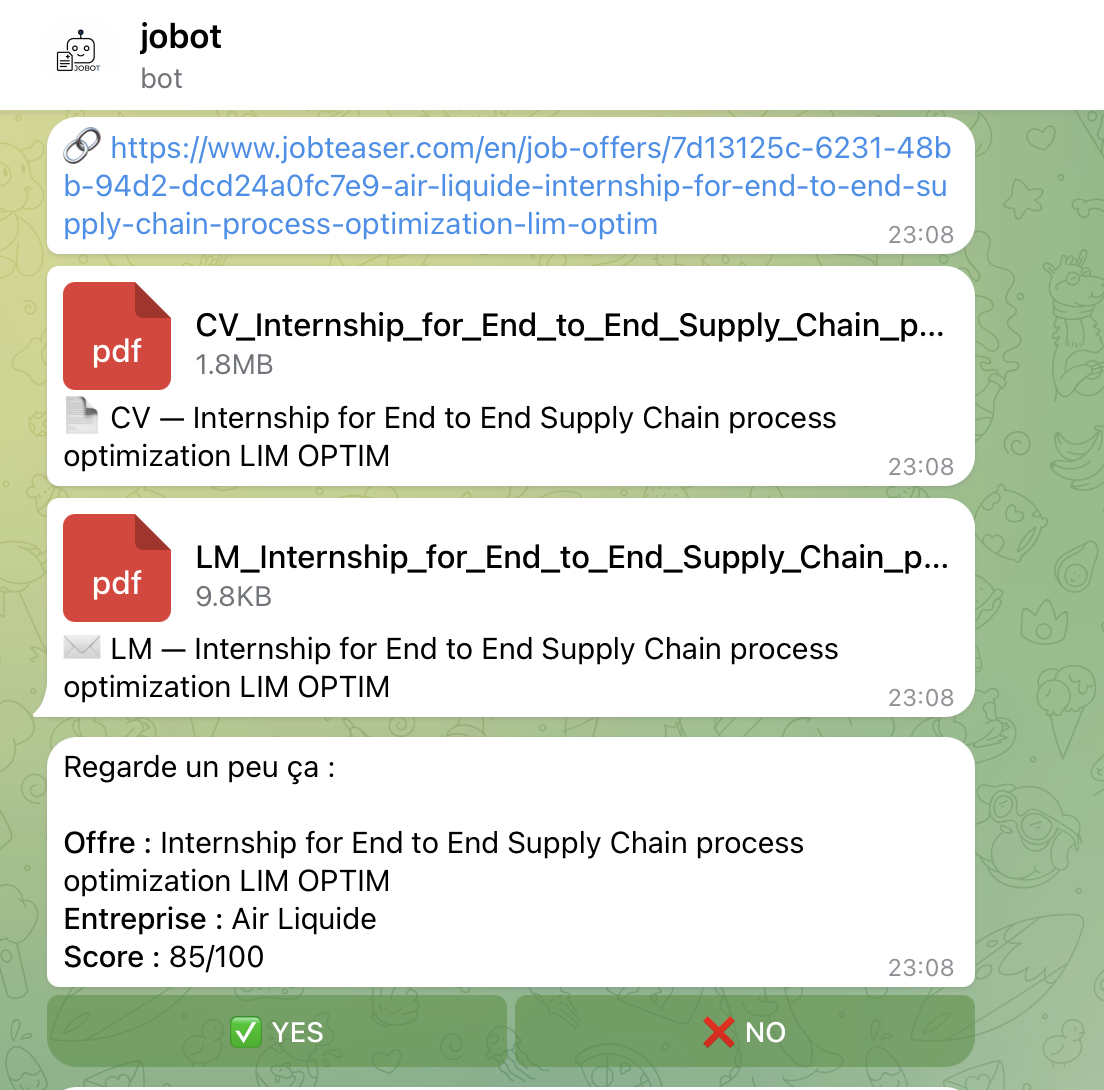
Step 4 — Telegram Notification (python-telegram-bot): All results are pushed to a private Telegram bot. For each offer, the bot sends the offer URL, the generated CV and cover letter as PDF documents, and an interactive summary showing the company name, offer title, and AI score out of 100. Each summary includes YES / NO inline buttons — I can review and approve or reject each application directly from my phone.
Here is the Telegram bot interface. Each offer is sent with its URL, the tailored CV and cover letter PDFs, and an interactive summary with YES / NO buttons for instant decision-making from my phone.
Step 5 — CI/CD Automation (GitHub Actions): The entire pipeline runs autonomously via a GitHub Actions workflow, scheduled twice daily (11:00 AM and 4:00 PM). The workflow sets up Python, installs all dependencies, pulls and caches the Ollama LLM model, runs the full pipeline, and uploads all outputs as artifacts. The model cache is persisted between runs to avoid re-downloading the ~2GB model each time.
RESULTS
The pipeline successfully processes up to 9 job offers per run, scoring and generating complete application packages in a single automated execution. The system has been running daily since February 2026, producing over 60+ complete runs with tailored CVs and cover letters for companies such as L'Oréal, CHANEL, Louis Vuitton, Deloitte, Allianz, Ferrero, Ubisoft, Wavestone, and Volkswagen — all without any manual effort beyond pressing YES or NO on Telegram.
The system requires zero daily effort: it runs entirely in the cloud via GitHub Actions with no local setup needed. The AI uses structured multi-step prompt chains with strict no-hallucination rules and JSON-only output. Every run produces timestamped output folders with full traceability — raw scraped data, enriched data, scoring results, match data, PDFs, and decision logs. The modular architecture (init → scraper → IA → PDF gen → Telegram → auto-apply) makes it easy to extend or replace any step independently.
Skills and Software Used
- Python
- Web scraping
- AI
- Data Pipeline
- Telegram Bot API
- Automation